Jeff Sauro, PhD March 15, 2011
ユーザーにあるタスクを完了してもらえば、それがどれだけ難しかったかを伝えてもらうことはできます。
しかし、ユーザーがタスクに挑戦することなく、そのタスクの難しさを伝えることができるでしょうか。
タスクの説明を見れば、タスクの複雑さが大抵はわかるので、ユーザーは実際のタスクの簡単さや難しさを適度に予測できることがわかります。
期待値とのギャップは、ユーザビリティ問題の強力な予測因子となります。最近では、eBayの例があります。
ユーザビリティテストでは、ユーザに代表的なタスクを完了してもらいます。ユーザーがこれらのタスクに挑戦する様子を観察することで、インタラクションの長所と短所に関する豊富な情報を得ることができます。
たった一人のユーザーが共通のタスクに苦心している様子を見るだけで、開発者やプロダクトマネージャーの心に残る印象を与えることができ、説得力のあるハイライトビデオを作ることができます。
主に定性的な活動(デザインの問題点を探して説明すること)は、簡単な合否判定基準を収集して完了率を報告することで、簡単に定量化できます。
ユーザーがタスクを完了するのがどれだけ難しいと考えているか、たった一つの質問をするだけでも価値があります。また、時間の経過とともに平均評価が向上することは、いかにデザインによってユーザーエクスペリエンスが向上させたかという風にも見て取れます。このような主観的な尺度は、すでに高い完了率を達成している場合に特に役立ちます。100%の完了率を改善することはできませんが、ユーザーが苦労して完了し、難しいと思ったタスクを改善することはできます。
タスク難易度の予測
良いタスクシナリオを書くには、練習が必要です。ユーザーを誘導しないこと、行動不可能にしないこと、事前に定義された具体的な成功基準を用意することです(Dumas & Redish第12章参照)。ユーザーにタスクを依頼すると、ユーザーは頼まれたことをすぐに解釈し、それがどれほど難しいかをある程度把握します。
例えば、IRSのフォームや税額表を使って、控除を考慮した後の調整後総所得を計算するように頼んだとしたら、それは地元のデパートの営業時間をオンラインで調べるよりも難しいことだと思うでしょう。
何百ものタスクシナリオを書き、何千人ものユーザーに挑戦してもらった経験から、私はタスクシナリオにどれだけの難易度が組み込まれているかを考えました。では、実際にテストすることなく、ユーザーにタスクの難易度を尋ねるだけでは、評価はどの程度正確になるのでしょうか。
期待以上の成果
Albert & Dixonが報告した研究(Is This What You Expected? The Use of Expectation Measures in Usability Testing 2003)では、ユーザーはあるタスクがどれだけ難しいと予想しているかを7段階で評価し(SEQと同様)、次にそのタスクを試して、どれだけ難しいと思ったかを同じ7段階で評価しました。
予想された難易度と実際の難易度の差から、いくつかの興味深い洞察が得られました。予想よりも難しかった課題は、改善の余地があると考えられます。予想以上に良かったタスクは、昇進の可能性があります。
私はこのアプローチを気に入っていますが、今回の研究のために少し変更する必要があります。同じユーザーに難易度の予測と評価をさせることで、バイアスがかかる可能性があるという問題があります。例えば、前回の評価を思い出したユーザーは、2回目の評価をする際に一貫性を持たせたいと思うかもしれません。このようなバイアスの可能性を排除するために、私は異なるユーザーのセットを使用しました(被験者間アプローチ)。
あるグループのユーザーには、一連のタスクの難易度を評価してもらいました。そして、別のグループのユーザーに実際にタスクを試してもらい、どれくらい難しいと思うかを評価してもらいました。下の表に示すように、さまざまな難易度のタスクを組み合わせて、有名なウェブサイト(Craigslist.com、Apple.com、Amazon.com、eBay.com、CrateandBarrel.com)を使用しました。
ラベル:タスクの説明
- Amazon DVD:100枚のDVDをAmazon.comで購入し、翌日にアメリカ国内の顧客に配送するためのコストを調べる。
- Apple 最安値のiPad:Apple.comで最安値のiPadを見つける。
- Apple エラーメッセージ:iPadの「iTunesに接続してください」というエラーメッセージの原因を調べ、Apple.comのウェブサイトで可能な解決策を見つける。
- Craigslist 求職投稿:クレイグスリストに2ヶ月間、3つのカテゴリーでプログラミングの仕事を掲載するための費用を調べる。
- Craigslist アパートの発見:Craigslistでサンフランシスコの2ベッドルームで家賃が月2000ドル以下のアパートを探す。
- eBay 出品手数料:eBayでiPhone 3GSを販売する際の手数料を見積もる。
- eBay 商品の発見:Camtasia Studio 7のコピーがeBayで販売されているかどうかを判断します。
- Crate &Barrel:営業時間 コロラド州デンバー(郵便番号80210)にあるCrate & Barrelの店舗が日曜日に営業しているかどうかを調べます。
結果
予測の精度はどの程度だったのでしょうか?実際の評価との絶対的な偏差は、全タスクで平均17%でした。予測値が実際の評価に非常に近いことに驚きました。4つの課題で、その差は10%以下でした。
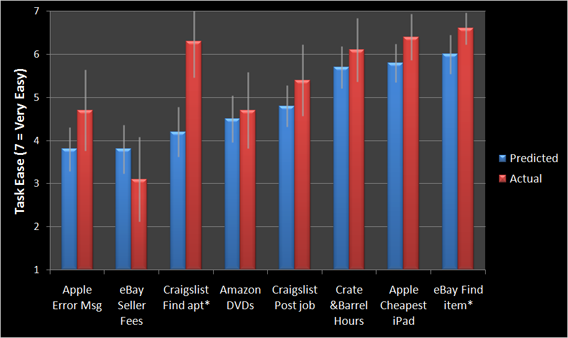
最も顕著なミスは、「Craigslist アパートの発見」タスクの難易度をユーザーが50%過剰に予測したことです。なぜか、これはかなり難しいと思われていたようです。これは、SFの賃貸市場にあまり詳しくないことが関係しているのではないかと思いました。データを見てみると、カリフォルニア以外の地域の人はこのタスクをより難しいと評価していましたが、カリフォルニア在住の人でもCraigslistでアパートを探すのは実際よりも難しいと考えていたようです。
eBay出品料変更の予測
一般的に、ユーザーはタスクの難易度を過大に予測する傾向がありました(8つのタスクのうち7つで)。予想以上に難しかったのは、「eBay 出品手数料」のタスクでした。ほとんどの人は、eBayで何かを売るために手数料を支払うことを想定していると思いますが、料金体系はもっとわかりやすいものだと予想していたようです。このタスクが難しいのは、複数の変数(販売価格の合計、送料、商品の種類など)があるためです。
しかし、eBayが料金体系の改善を発表したばかりなので、このタスクが難しすぎると思ったのはこのユーザーだけではないようです。この質問は、eBayの価格変更の数週間前に行われたものですが、予想の尺度がいかに強力で予測的であるかを示しています。
予測されたスコアが実際のスコアをどの程度説明できるかを理解するために、タスクレベルで単純な線形回帰を行いました。タスクの難易度の変動の半分は、異なるユーザーセットがそのタスクをどのように考えるかによって説明できます(調整後R2 = 50.8%)。下の散布図は、この強い関連性を示しています。CraigslistとeBayのタスクがハイライトされており、トレンドラインからの乖離が予想との違いを示しています。
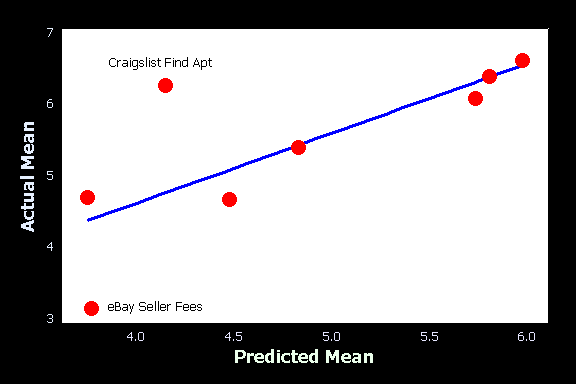
タスクの数が増えれば(特に期待外れのタスクが増えれば)、ユーザーのタスク予測能力は低下すると思われます。しかし、このデータは、ユーザビリティの認識(あるいは認識不足)の大部分がタスクシナリオに含まれていることを示唆しています。
結論
タスクレベルの評価の半分は、ウェブサイトとのインタラクションではなく、タスク・シナリオの固有の難しさだけで説明できる。ユーザーはタスクの難易度を過大評価している可能性が高く、ユーザビリティの問題に遭遇した場合にのみ、予想よりも低い評価をする。
予測評価と実際の評価の間には強い関連性がありますが、期待のずれがどこに存在するかを特定するためには、ユーザーにタスクを試してもらう必要があります。優れたベンチマークや比較テストがない場合、期待値評価を使用することは、完了率やUIの問題数ではわからない、潜在的なインタラクションの問題を診断するのに役立ちます。