https://help.qualaroo.com/hc/en-us/articles/360039069992-Single-Ease-Question-SEQ-
Anastacia Valdespino 2 years ago Updated
この記事で紹介されている内容
- SEQとは?
- SEQの使い方
- SEQの結果を解釈する
- SEQの長所と短所
シングル・イーズ・クエスチョン(Single Ease Question:SEQ)とは?
シングル・イーズ・クエスチョン(Single Easy Question:SEQ)とは、ウェブサイトやアプリの特定のタスクをユーザーがどれだけ難しいと感じるか、あるいは簡単だと感じるかを評価するための7段階の評価尺度のことです。SEQは、ユーザビリティテストの重要な部分です。SEQは、インターフェースやプロトタイプの一般的な使い勝手を測定するのではなく、ユーザーが感じた特定のタスクを完了するための難易度を測定します。

SEQで何が分かるのか?
SEQは、特定のタスクの難易度に関するユーザーの認識を知るためのものです。ユーザーがタスクにどれだけ苦労したか(あるいは苦労しなかったか)を客観的な尺度で表現することは必ずしも容易ではありませんが、SEQは知覚された難しさを定量化するために使用できます。
また、タスクレベルで質問をすることで、ユーザーにとって障害となるタスクを特定することができます。他のタスクの難易度に関するデータがある場合、SEQの結果は、特に困難な障害を容易に特定できる比較指標となります。ジェフ・サウロは、SEQのような要素を他のデータと比較するという記事の中で、この考え方を説明しています。
SEQは、主観的になりがちな「難しさ」という概念を数値化したものです。SEQを比較することで、ユーザーの摩擦を減らすことができる特定のエリアの流れやインターフェースの部分を見つけることができます。
どのようなときに使うのか?
SEQは、ユーザーが1つの特定のタスクを実行した直後に使用します。なお、SEQは、ユーザーがタスクを正常に完了しなかった場合にも使用できます。
UXプロセスにおいて、SEQは、プロトタイプをテストしたり、実際のWebサイトやアプリでユーザビリティテストを行い、ユーザーエクスペリエンスを向上させるときに最も有効です。プロトタイプの段階でSEQ Nudgesを投与すると、ユーザビリティに関する明確な洞察が得られ、デプロイ前のプロトタイプの改善に役立ちます。
もちろん、検証段階で本番の製品のユーザビリティをテストし、どのような変更を加えればユーザーエクスペリエンスがよりスムーズになるかを判断する際にも、SEQは有効です。
SEQはタスクが実行された後に使用されるべきものなので、ナッジのターゲットを正しく設定することが重要です。配置やタイミングを誤ると、間違ったタイミングで質問をしてしまい、関連性の低いインサイトを収集してしまう危険性があります。
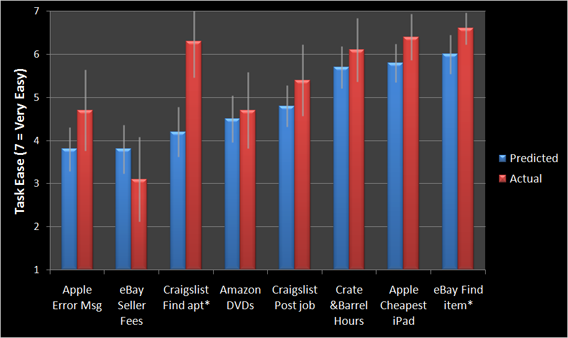
最良の結果を得るためには、あるタスクのSEQを他のタスクのスコアと比較する必要があります。これにより、ユーザーにとってユーザーエクスペリエンスのどの部分が最も難しいかを判断することができ、戦略的に改善に取り組むことができます。
SEQの使い方
テンプレート設定
SEQは、業界標準の調査の一つであり、私たちのテンプレートの発売と同時にコミュニティに提供できることを嬉しく思います。以下では、SEQテンプレートの使用方法をご紹介します。
Qualarooならたった3ステップでSEQの運用!
- 正しいチャンネルを選択
- ナッジを実行する場所(デスクトップ、モバイルウェブ、プロトタイプ、モバイルアプリ)を決め、"テンプレートを選択 "を選択します。
- このアンケートは、組織が必要とする数のチャンネルで実施することができます。追加のアンケートを作成して、組織がカバーするさまざまなドメインをカバーすることができます。
- テンプレートの検索
- 事前に検証されたテンプレートのリストから「SEQ」を選択します。検索バーに「SEQ」と入力すると、検証済み/プロトタイプでフィルタリングして探すことができます。
- 表現が若干異なる2種類のバージョンがあることにご注意ください。お好きな方をお選びください。
- アンケートの作成、編集、公開
- タイミングを見計らって気をつけること:
- ユーザーの離脱意図に基づくターゲティングは一般的な戦略であり、Qualarooでは簡単に行うことができます。タスクを完了する前にページを去ろうとしている参加者は、タスクの難易度が高いと解釈することができます。これはSEQを起動するための理想的なタイミングかもしれません。
- 調査しているタスクを完了するのにかかる平均時間を決定し、その情報を使って質問の時間を決めます。この部分は、一般的な見積もりではなく、あなたの製品やウェブサイトでの具体的な経験に合わせて作ることをお勧めします。というのも、インターフェイスが異なると、同じようなタスクをこなすのにかかる時間も変わってくるからです。あるアプリへのログインは簡単で1分程度で済むかもしれませんが、家具などの大きな買い物の詳細を決めるような判断や作業は、それほど簡単ではありません。何人かの参加者でテストした後、必要に応じてナッジのタイミングを調整することができます。
- SEQは非常に簡単なので、ターゲットやタイミングを正しく設定すること以外は、あまりカスタマイズする必要はありません。
- タイミングを見計らって気をつけること:
結果の解釈
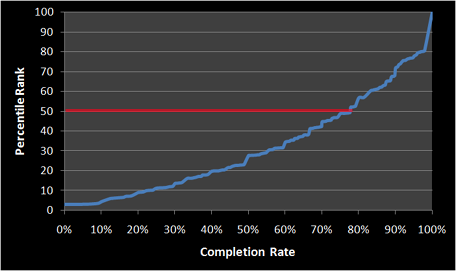
SEQの結果を解釈する際の良い点は、反応がいかに単純であるかということです。MeasuringUによると、平均的な回答は5.3から5.6の間です。このベンチマークは、ユーザーにとってどのタスクが特に簡単または難しいかを判断するのに役立ちます。
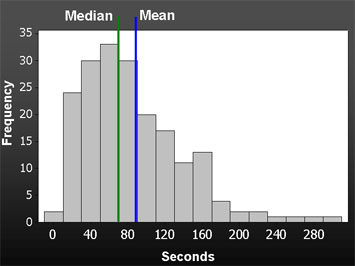
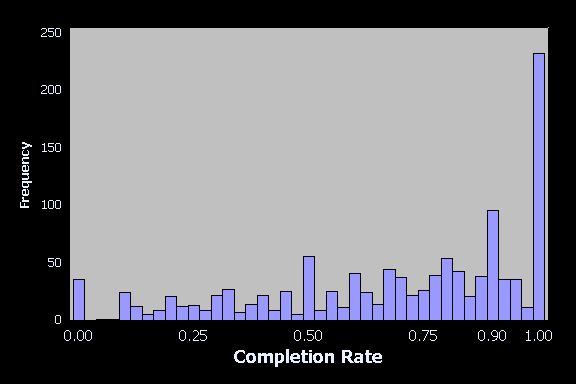
ユーザーにとって最大の違いをもたらす改善点を見つけるために、このデータを比較して使用することを強くお勧めします。さらにデータを活用したい場合は、Jeff Sauro氏によるSEQを使ったタスクの完了率と時間の推定についての記事をご覧ください。

SEQの長所と短所
長所
- SEQほどシンプルなものはありません。1つの質問と数値による回答だけで、SEQは非常にシンプルで、特にテンプレートの助けを借りれば、すぐに運用を開始することができます。 そのシンプルさにもかかわらず、SEQはより複雑なアプローチと同等かそれ以上のパフォーマンスを発揮します。(出典)
- シンプルなスコアリングはシンプルな解釈も意味しています。あなたは回答を平均化するだけでいいので、ある言葉の選択の意味を考えるために多くの時間を費やす必要はありません。
- SEQはタスクを実行した直後に質問することになっているので、データは具体的であるだけでなく、記憶が新鮮なので正確であるはずです。
短所
- SEQの最大の利点の一つであるシンプルさは、弱点とも言えます。SEQはたった1つの質問であり、自由形式の要素が含まれていないため、受け取った回答についてより良い状況を得るために、理由を尋ねることをお勧めします。
- 検証が必要となる点も弱点です。特定のタスクが非常に難しいと評価された場合、そのタスクを完了するためにユーザーが要した平均時間と完了率を見て、実際にどれくらい難しいのかをよりよく理解したいと思うかもしれません。MeasuringUが言うところでは、「SEQのような態度データの検証には、態度(直接観察できないもの)に割り当てられた数字が、行動(直接観察できるもの)にどのように対応しているかを示すことが含まれている。」ということです。 これはなぜなのでしょうか?−−SEQは態度を測定するものであり、それは本質的に主観的なものだからです。
結論
SEQは、ユーザビリティテストの作業に集中するための素晴らしい方法です。SEQは、タスクの全体的な体験についての漠然とした印象を記録するのではなく、タスクに特化しているため、粒度が細かくなるように設計されています。もちろん、多くのシンプルな調査と同様に、実用的な洞察を得るためには、回答を文脈に沿って検討する必要があります。
ご質問がある場合や、このテンプレートの設定についてカスタマーサクセスマネージャーに連絡を取りたい場合は、こちらからリクエストを送信してください。私たちは、Qualarooがお客様にとってより使いやすく、より満足度の高い、お客様のニーズに合った便利なものになるよう、常に検討しています。
利用可能なチャンネル
- ウェブ・デスクトップ
- ウェブ・モバイル
- リンク
- プロトタイプ